Image classification task using Naive Bayes and logistic regression classifier
Using OpenCV, a user can interact and play around with a lot of media like images, videos.
Following process is carried out in the classification:
- Read the Images from training set, and scale them to unique size.
- Extract the features out of images using Singular Value Decomposition.
- Perform the logistic regression on the images with all features and extracted features.
- Perform the naive bayes on the images with all features and extracted features.
Dataset for this task has been downloaded from here.
Import necessary libraries.
import os, cv2, itertools
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
%matplotlib inline
train_dir = 'input/train2/' # Directory for training set
test_dir = 'input/test2/' # Directory for testing set
# Images are of various sizes, therefore, all the images needs to be downscaled to size 64*64
ROWS = 64
COLS = 64
CHANNELS = 3
train_images = [train_dir+i for i in os.listdir(train_dir)] # use this for full dataset
test_images = [test_dir+i for i in os.listdir(test_dir)]
# Read the images as coloured and resize them as 64*64*3 (x * y * rgb)
def read_image(file_path):
img = cv2.imread(file_path, cv2.IMREAD_COLOR)
return cv2.resize(img, (ROWS, COLS), interpolation=cv2.INTER_CUBIC)
# Prepare the training set and classes as dog and cat
def prep_data(images):
m = len(images)
n_x = ROWS * COLS * CHANNELS
X = np.ndarray((n_x, m), dtype=np.uint8)
y = np.zeros((1, m))
print ("X shape is {}".format(X.shape))
for i, image_file in enumerate(images):
image = read_image(image_file)
X[:, i] = np.squeeze(image.reshape((n_x, 1)))
if 'dog' in image_file.lower():
y[0, i] = 1
elif 'cat' in image_file.lower():
y[0, i] = 0
else:# if neither dog nor cat exist, return the image index (this is the case for test data)
y[0, i] = image_file.split('/')[-1].split('.')[0]
if i%1000 == 0: print('Processed {} of {}'.format(i, m))
return X, y
X_train, y_train = prep_data(train_images)
X_test, test_idx = prep_data(test_images)
#Shape-> (Features, Number of Images)
print("Train shape: {}".format(X_train.shape))
print("Test shape: {}".format(X_test.shape))
X shape is (12288, 65)
Processed 0 of 65
X shape is (12288, 30)
Processed 0 of 30
Train shape: (12288, 65)
Test shape: (12288, 30)
SVD Based Features SVD is used for dimensionality reduction, however, incase of images dimensionality reduction can loose to degradation of model performance
U, D, V = np.linalg.svd(X_train)
X_train_svd = np.matrix(U[:, :2]) * np.diag(D[:2]) * np.matrix(V[:2, :])
print(X_train_svd.T.shape)
U, D, V = np.linalg.svd(X_test)
X_test_svd = np.matrix(U[:, :2]) * np.diag(D[:2]) * np.matrix(V[:2, :])
print(X_train_svd.T.shape)
(65, 12288)
(65, 12288)
Check the extracted feature image
classes = {0:'cat',
1:'dog'}
# Function to show a specific image
def show_image(X, y, idx):
image = X[idx]
image = image.reshape((64,64, CHANNELS))
plt.figure(figsize=(4,2))
plt.imshow(image)
plt.title("This is a {}".format(classes[y[idx,0]]))
plt.axis("off")
plt.show()
# Function to show predicted image
def show_image_prediction(X, idx, model):
image = X[idx].reshape(1, -1)
image_class = classes[model.predict(image).item()]
image = image.reshape((ROWS, COLS, CHANNELS))
plt.figure(figsize=(4,2))
plt.imshow(image)
plt.title("Test {}: I think this is a {}".format(idx, image_class))
plt.axis("off")
plt.show()
# Check the reduced size image from training set
show_image(X_train.T, y_train.T, 0)

Logistic Regression Model with all the features
from sklearn.linear_model import LogisticRegressionCV
from sklearn.metrics import confusion_matrix
clf = LogisticRegressionCV( max_iter=10000 )
X_train_lr, y_train_lr = X_train.T, y_train.T.ravel()
clf.fit(X_train_lr, y_train_lr)
LogisticRegressionCV(Cs=10, class_weight=None, cv='warn', dual=False,
fit_intercept=True, intercept_scaling=1.0, l1_ratios=None,
max_iter=10000, multi_class='warn', n_jobs=None,
penalty='l2', random_state=None, refit=True, scoring=None,
solver='lbfgs', tol=0.0001, verbose=0)
Logistic Regression Model with SVD features
clf_svd = LogisticRegressionCV( max_iter=10000 )
X_train_lr_svd, y_train_lr_svd = X_train_svd.T, y_train.T.ravel()
clf_svd.fit(X_train_lr_svd, y_train_lr_svd)
LogisticRegressionCV(Cs=10, class_weight=None, cv='warn', dual=False,
fit_intercept=True, intercept_scaling=1.0, l1_ratios=None,
max_iter=10000, multi_class='warn', n_jobs=None,
penalty='l2', random_state=None, refit=True, scoring=None,
solver='lbfgs', tol=0.0001, verbose=0)
# Function to plot the confusion matrix for specific model.
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
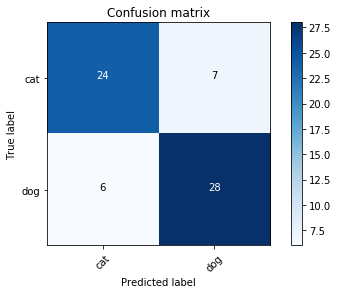
LR Confusion Matrix for All features
print("LR Model(All features) accuracy: {:.2f}%".format(clf.score(X_train_lr, y_train_lr)*100))
plot_confusion_matrix(confusion_matrix(y_train_lr, clf.predict(X_train_lr)), ['cat', 'dog'])
LR Model(All features) accuracy: 100.00%
Confusion matrix, without normalization
[[31 0]
[ 0 34]]
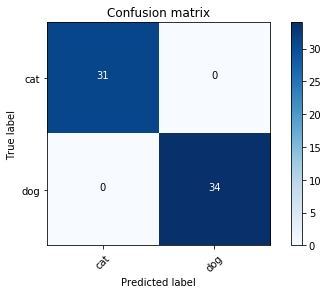
LR Confusion Matrix for SVD features
It can be noticed that with SVD features, accuracy of model is degraded.
print("LR Model(SVD features) accuracy: {:.2f}%".format(clf_svd.score(X_train_lr_svd, y_train_lr_svd)*100))
plot_confusion_matrix(confusion_matrix(y_train_lr_svd, clf_svd.predict(X_train_lr_svd)), ['cat', 'dog'])
LR Model(SVD features) accuracy: 53.85%
Confusion matrix, without normalization
[[ 6 25]
[ 5 29]]

# Test the prediction of the Model
X_test_lr, test_idx = X_test.T, test_idx.T
for i in np.random.randint(0, len(X_test_lr), 1):
show_image_prediction(X_test_lr, i, clf)

Naive Bayes with all the features
from sklearn.naive_bayes import GaussianNB
nb = GaussianNB()
nb.fit(X_train_lr, y_train_lr)
GaussianNB(priors=None, var_smoothing=1e-09)
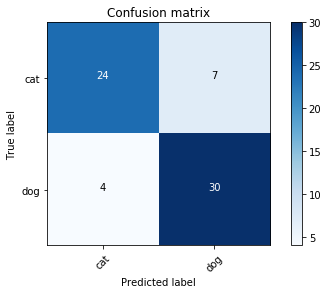
print("NB Model(All features) accuracy: {:.2f}%".format(nb.score(X_train_lr, y_train_lr)*100))
plot_confusion_matrix(confusion_matrix(y_train_lr, nb.predict(X_train_lr)), ['cat', 'dog'])
NB Model(All features) accuracy: 83.08%
Confusion matrix, without normalization
[[24 7]
[ 4 30]]
X_test_lr, test_idx = X_test.T, test_idx.T
for i in np.random.randint(0, len(X_test_lr), 1):
show_image_prediction(X_test_lr, i, nb)

Models with Intensity based features
def read_image_intense(file_path):
img = cv2.imread(file_path, cv2.IMREAD_COLOR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# neg = 255 - img
return cv2.resize(gray, (ROWS, COLS), interpolation=cv2.INTER_CUBIC)
def prep_data_intense(images):
m = len(images)
n_x = ROWS * COLS
X = np.ndarray((n_x, m), dtype=np.uint8)
y = np.zeros((1, m))
print ("X shape is {}".format(X.shape))
for i, image_file in enumerate(images):
image = read_image_intense(image_file)
X[:, i] = np.squeeze(image.reshape((n_x, 1)))
if 'dog' in image_file.lower():
y[0, i] = 1
elif 'cat' in image_file.lower():
y[0, i] = 0
else:# if neither dog nor cat exist, return the image index (this is the case for test data)
y[0, i] = image_file.split('/')[-1].split('.')[0]
if i%1000 == 0: print('Processed {} of {}'.format(i, m))
return X, y
X_train_i, y_train_i = prep_data_intense(train_images)
X_test_i, test_idx_i = prep_data_intense(test_images)
print("Train shape: {}".format(X_train_i.shape))
print("Test shape: {}".format(X_test_i.shape))
X shape is (4096, 65)
Processed 0 of 65
X shape is (4096, 30)
Processed 0 of 30
Train shape: (4096, 65)
Test shape: (4096, 30)
def show_image_intense(X, y, idx):
image = X[idx]
image = image.reshape((64,64))
plt.figure(figsize=(4,2))
plt.imshow(image)
plt.title("This is a {}".format(classes[y[idx,0]]))
plt.axis("off")
plt.show()
def show_image_prediction_intense(X, idx, model):
image = X[idx].reshape(1, -1)
image_class = classes[model.predict(image).item()]
image = image.reshape((ROWS, COLS))
plt.figure(figsize=(4,2))
plt.imshow(image)
plt.title("Test {}: I think this is a {}".format(idx, image_class))
plt.axis("off")
plt.show()
show_image_intense(X_train_i.T, y_train_i.T, 0)

LR Model on intensity based features
clf_i = LogisticRegressionCV( max_iter=10000 )
X_train_in, y_train_in = X_train_i.T, y_train_i.T.ravel()
clf_i.fit(X_train_in, y_train_in)
LogisticRegressionCV(Cs=10, class_weight=None, cv='warn', dual=False,
fit_intercept=True, intercept_scaling=1.0, l1_ratios=None,
max_iter=10000, multi_class='warn', n_jobs=None,
penalty='l2', random_state=None, refit=True, scoring=None,
solver='lbfgs', tol=0.0001, verbose=0)
print("LR Model(Intensity) accuracy: {:.2f}%".format(clf_i.score(X_train_in, y_train_in)*100))
plot_confusion_matrix(confusion_matrix(y_train_in, clf_i.predict(X_train_in)), ['cat', 'dog'])
LR Model(Intensity) accuracy: 100.00%
Confusion matrix, without normalization
[[31 0]
[ 0 34]]
X_test_i, test_idx_i = X_test_i.T, test_idx_i.T
for i in np.random.randint(0, len(X_test_i), 1):
show_image_prediction_intense(X_test_i, i, clf_i)

Naive Bayes Model for intensity features
nb_i = GaussianNB()
X_train_in, y_train_in = X_train_i.T, y_train_i.T.ravel()
nb_i.fit(X_train_in, y_train_in)
GaussianNB(priors=None, var_smoothing=1e-09)
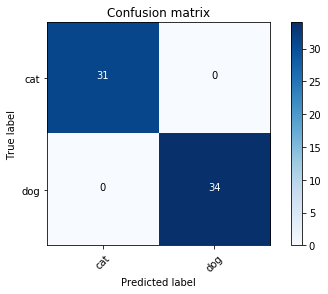
print("NB Model(Intensity) accuracy: {:.2f}%".format(nb_i.score(X_train_in, y_train_in)*100))
plot_confusion_matrix(confusion_matrix(y_train_in, nb_i.predict(X_train_in)), ['cat', 'dog'])
NB Model(Intensity) accuracy: 80.00%
Confusion matrix, without normalization
[[24 7]
[ 6 28]]